Questo è l'Archivio del Magazine Poliflash per gli anni 2016-2022.
Gli articoli della edizione corrente sono disponibili sul nuovo sito.
Gli articoli della edizione corrente sono disponibili sul nuovo sito.

Creare un modello di Intelligenza Artificiale in italiano di grande scala, che associa immagini al testo e permette di svolgere un insieme di task come ricerca di immagini e classificazione: questo l’obiettivo del progetto CLIP-Italian, sviluppato da Giuseppe Attanasio – dottorando del Dipartimento di Automatica e Informatica del Politecnico – che ha lavorato in collaborazione con i colleghi Federico Bianchi (Università Bocconi), Raphael Pisoni (ricercatore indipendente), Silvia Terragni (Università Milano Bicocca), Gabriele Sarti (Università di Groningen) e Sri Lakshmi (ricercatrice indipendente).
Il progetto è arrivato tra i 15 finalisti della competizione internazionale tenutasi nel contesto della HuggingFace Flax/JAX Community Week, resa possibile dai fondi messi a disposizione da Google e HuggingFace - società leader nei campi del machine learning e del natural language processing (NLP) - che ha diffuso il modello sulla sua piattaforma. CLIP-Italian ha poi ricevuto una menzione speciale nella seconda fase della competizione, ottenendo accesso ad ulteriori risorse per lo sviluppo del progetto, a cui è stato dedicato anche un articolo su ArXiv.
CLIP-Italian è al momento l’unico modello di machine learning per classificare immagini in lingua italiana e si basa appunto su CLIP. Quest’ultimo è uno dei modelli di machine learning attualmente più avanzati rilasciato dall’azienda OpenAI, in grado di apprendere in modo efficiente le classi di oggetti osservate in fase di addestramento (training), associando concetti visuali più complessi alle relative rappresentazioni testuali.

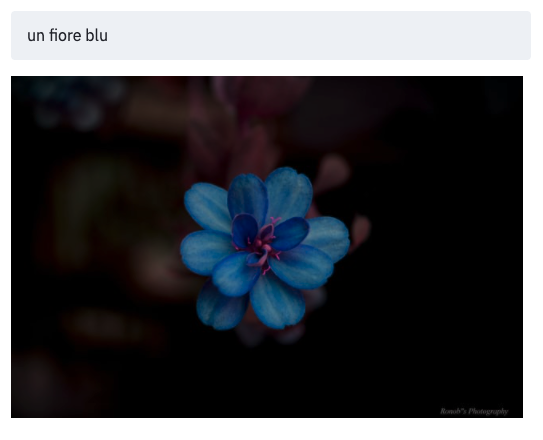


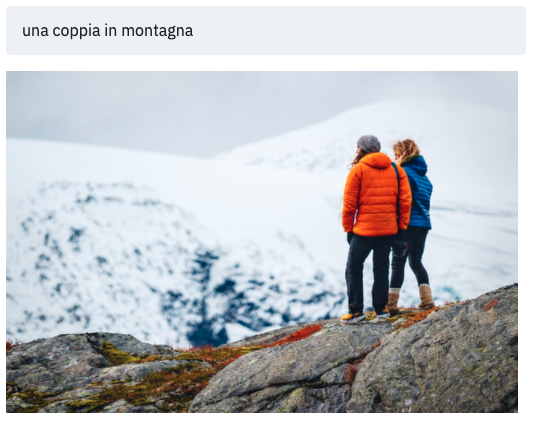
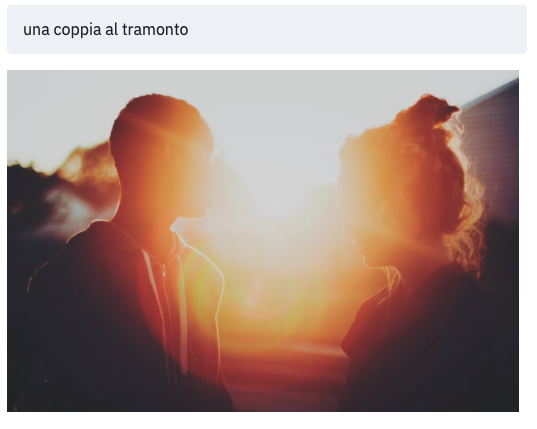
Nella galleria alcuni esempi di ricerca di immagini che il modello non ha mai visto in fase di addestramento. Nonostante siano del tutto "nuove", il modello riesce ad associarle correttamente ai testi [Fonte immagini: The Unsplash Dataset 25K]
Il modello consiste nell’associare le immagini e le loro descrizioni, unendo l’apprendimento delle immagini con l’analisi del linguaggio naturale utilizzato per effettuare le ricerche. Infatti alla base di CLIP c’è una rete neurale che si contraddistingue per la flessibilità nelle applicazioni e che per questo riesce a rendere più semplice la ricerca di immagini a partire da una descrizione testuale.
Con CLIP-Italian, Attanasio e colleghi hanno messo a punto un’estensione di CLIP che permette di eseguire sia una classificazione “zero-shot” - ovvero identificare oggetti e concetti nelle immagini senza aver addestrato la rete specificatamente su questo task - sia un task di ricerca (image retrieval) a partire da frasi in italiano. È possibile provare sia la classificazione che la ricerca delle immagini sulla demo ufficiale del progetto.
Il lavoro di addestramento di CLIP-Italian si è basato su un dataset di circa 1,4 milioni di immagini, ciascuna delle quali associata a una descrizione in italiano. L’allestimento del dataset ha coinvolto anche una traduzione automatica, oltre ai dati originali. I risultati disponibili sul repository del progetto – accessibile su GitHub – mostrano come CLIP-Italian risulti essere un modello di altissima qualità.
Immagine di copertina: Fatos Bytyqi |Unsplash


